ACM Multimedia 2025于10月27日至10月31日在爱尔兰都柏林召开。哈尔滨工业大学(深圳)计算机应用研究中心漆舒汉课题组博士生肖鑫宇所完成的论文Multi-faceted Complementary Learning for Incomplete Multi-view Multi-label Classification荣获ACM Multimedia 2025杰出论文奖(outstanding Paper Award)。

图1:博士生肖鑫宇参会照片
ACM Multimedia 是多模态领域国际顶级学术会议之一。本次大会汇聚了来自学术界和产业界的顶尖专家,共同探索视频、触觉、虚拟现实与增强现实、音频、语音、音乐、传感器和社会数据等领域的尖端发展。ACM多媒体大会着重强调跨模态信息的整合与交换,鼓励具有重大技术突破潜力和积极实际应用价值的创新方法。自创办以来,ACM Multimedia已成为全球多模态研究者和工程师的重要交流平台,出版了众多具有广泛学术影响力的论文,并在学术界和工业界产生了深远影响。
本届会议于10月27日至10月31日在英国格拉斯哥召开,会议共收到投稿4711篇,共有1251篇论文被接收,录用率为26.6%,最终评选出12篇杰出论文奖。
获奖链接:https://acmmm2025.org/awards/

论文摘要
由于数据收集和标注可靠性的限制,多视角数据的缺失会削弱对样本的全面理解,不完整的多视角多标签分类面临严峻挑战。为了解决这个问题,作者提出了一种多视角互补学习框架MC-IVLC,以充分挖掘不同视角之间的互补信息。具体而言,MC-IVLC旨在补偿重构特征的坍塌,并显式地使用融合特征作为监督信号来指导缺失视角的补全。此外,MC-IVLC从实例和语义两个层面充分利用了视角之间的互补关系。实例层面的对比学习旨在促进同一视角中相似特征的聚类,从而增强跨视角特征的互补性。语义层面的对比学习利用伪标签来推断标签嵌入中缺失的标签。它将伪标签的语义信息与特征嵌入相结合,以指导跨视角特征的语义相关性。最后,MC-IVLC显式编码了视图标识,并引入了视图标签预测损失项,以增强对视图信息的感知,并对齐单个视图和多个视图,进一步探索视图和标签之间的内在联系。我们在五个广泛使用的数据集上进行了实验。实验结果表明,与现有最佳方法相比,MC-IVLC取得了优异的性能。
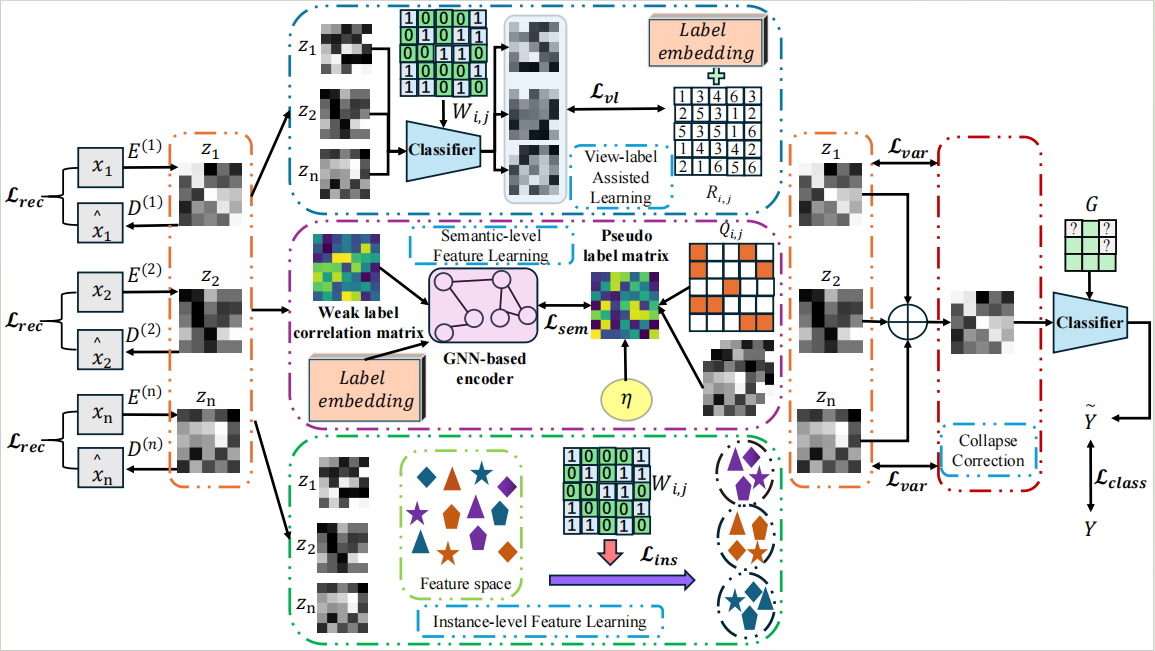
图2:论文框架图
作者介绍
第一作者:肖鑫宇,哈尔滨工业大学(深圳)2023级博士研究生,研究方向为模态部分缺失下的多模态学习,多模态大模型具身智能。目前以第一作者/共同第一作者身份发表CCF-A类会议论文1篇、CCF-B类会议论文1篇、IEEE 1区TOP Trans 1篇。
通讯作者:漆舒汉,哈尔滨工业大学(深圳)教授,博士生导师,鹏城实验室双聘研究学者,中国计算机学会(CCF)会员,YOCSEF(深圳)主席, CCF-多媒体专委会执行委员。曾任新加坡国立大学访问学者,腾讯优图实验室高级研究员。在国际著名学术会议和期刊上共发表论文50余篇,其中包括SIGIR, ICME, TMM,TNNLS等国际一流会议和期刊。与此同时,还是多个著名国际会议及期刊的委员及评委,其中包括IEEE TMM,IEEE TNNLS,IEEE TKDE,IJCAI等国际一流期刊和会议的审稿人。个人主持科研经费超过800万元,当前主持国家自然科学基金2项,广东省自然科学基金2项,参与国家重点研发计划共2项,中央军委重点项目3项。
