
论文链接:https://arxiv.org/pdf/2407.13863
Github链接:https://github.com/final-solution/IF-GMI
ECCV 2024 录用(Oral,Top 3%)
作者:哈尔滨工业大学(深圳)陈斌
(撰写:邱怡翔,审核:陈斌)
一、背景介绍:
近年来,深度神经网络(DNNs)经历了前所未有的发展,并在广泛的应用中取得了巨大的成功,包括人脸识别、个性化推荐和音频识别等。虽然深度神经网络给我们带来了许多实际的好处,但与之相关的对隐私和安全的关注也引起了极大的关注。最近的研究表明,深度神经网络存在一定的隐私泄露风险,因为对手可以从这些预先训练过的模型中揭示隐私信息[1]。其中,模型反演攻击由于其恢复收集和用于模型训练的隐私敏感数据集的强大能力而构成极大的威胁。
虽然近年来基于GAN的模型反演攻击在恢复高质量和隐私敏感的图像方面取得了很大的进展,但在某些情况下的有效性有限。一个典型的挑战是分布外场景,在这个场景中,目标私有数据集和在GAN先验训练过程中使用的公共数据集之间存在显著的分布偏移。
近年来,一些研究表明,GAN的隐向量和中间特征中编码着丰富的语义信息。受这些工作的启发,我们通过经验观察到,中间特征中编码的丰富语义信息有助于在更严格的设置下充分恢复高质量的私有数据,因此,有必要探索利用GAN的内在分层知识到MI攻击中的方法,从而缓解分布偏移问题。
二、方法概述:
2.1攻击目标
在本文中,我们主要关注在白盒设置下的MI攻击。该设置下,攻击者可获知目标模型的所有信息,包括结构、权重、输出等。我们主要关注图像分类任务,攻击者旨在利用目标分类器的输出预测置信度和其他辅助先验来重建给定身份的代表性隐私面部图像。
在基于GAN的模型反演攻击中,攻击者使用和目标私有数据集结构相似的公开数据集来训练专门设计的GAN,或者利用公共预先训练的GAN(本文使用预训练的StyleGAN2-Ada)。在攻击过程中,攻击者通过如下公式优化生成器G的输入隐向量z,优化后的隐向量 对应的生成图片即为重建的图像。
对应的生成图片即为重建的图像。

2.2 基于中间层特征优化的模型反演攻击

图1 IF-GMI算法流程
本文主要从优化过程对模型反演攻击进行改进,该过程主要分为初始化选择和中间层特征搜索优化两个部分,流程如图1所示。
2.2.1 初始化选择
隐向量的初始采样具有随机性,并且部分隐向量难以优化到较好的重建结果,导致攻击精度下降。为此,本文采用初始化选择技术对隐向量进行初始化选择。具体来说,我们首先采样大量隐向量并生成图像,进行一系列数据增强变换,并输入目标分类器获得相应置信度分数。通过选择得分较高的潜在向量进行进一步的优化,我们可以显著提高最终图像的质量,从而更好地接近目标分布。
2.2.2 中间层特征搜索优化
从直观上看,直接优化GAN先验的输入隐向量是获得理想重建图像的一种自然方法,这也是以往所有基于GAN的攻击方法采取的策略。然而,最近的研究表明,除了输入的隐向量外,GANs的中间特征中存在相当丰富的语义信息。例如对StyleGAN [2]而言,前面一部分层主要控制图像的高层次结构,如脸型、发型等;后面一部分层主要控制图像的细节。这促使我们超越了仅仅搜索输入隐空间的局限性,提出了一种更关注更接近输出的中间特征域的新方法,伪代码如图2所示。

图2 IF-GMI算法伪代码

三、实验:
3.1 选取中间层搜索层数L
我们在公共数据集为FFHQ,目标模型为在CelebA数据集上训练的DenseNet-169模型的实验设置上,对不同的中间层搜索层数L进行实验和比较,如图3所示。结果表明,中间层搜索的层数过小或者过大都会影响攻击效果。当L较小时,存在欠拟合的现象;当L过大时,会导致某些细节对目标模型过拟合,并产生不真实的图像。因而在实验中选取适中的L进行。
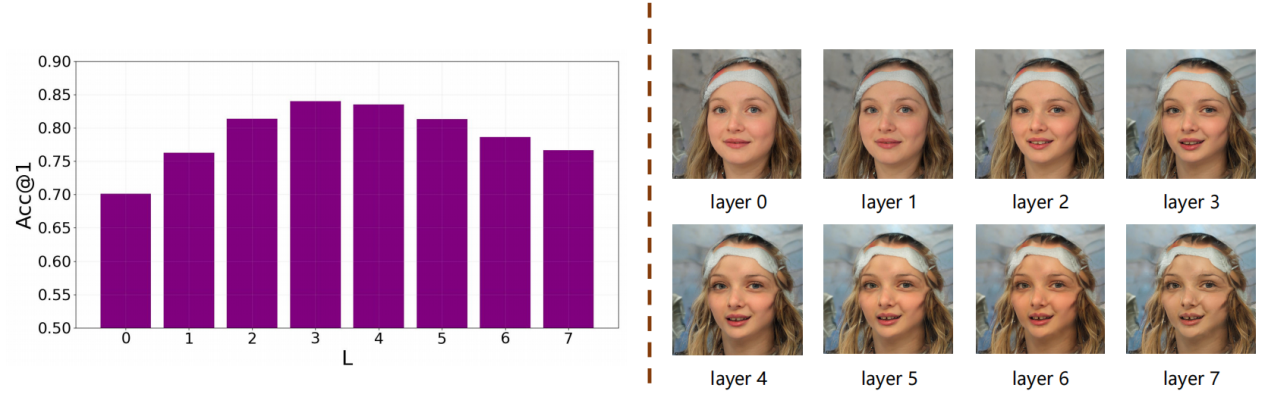
图3 不同中间层搜索层数L的攻击准确率及可视化
3.2 标准实验设置
我们在常见的高分辨率FFHQ与MetFaces两个公有数据集设置上进行实验,攻击目标为在FaceScrub私有数据集上训练的ResNet-152。其中,FFHQ与私有数据集的分布偏移较小,MetFaces的分布偏移较大。对比的基线主要有GMI [3],KEDMI [4],PPA [5],LOMMA [6],PLGMI [7]。表1结果表明,我们的方法的攻击效果显著优于以前的攻击算法,特别是分布偏移情况较大的情况下,以往的方法攻击效果遭受大幅度的下滑,而我们的方法仍能够保持很好的攻击效果。同时,由图4可知我们生成的图片具有更高的高保真度。

表1 针对在FaceScrub私有数据集上训练的ResNet-152的攻击结果

图4 针对在FaceScrub私有数据集上训练的ResNet-152的重建图片
3.3 不同的数据集和目标模型下的实验
在标准设置外,我们对不同私有数据集以及不同架构的目标模型的设置下进行实验,并与高分辨率下当前最好的攻击算法PPA [5]进行比较。对于前者,我们将私有数据集修改为CelebA,结果如表2所示;对于后者,我们分别对ResNet-152,ResNeSt-101,DenseNet-169三种目标模型进行攻击,结果如表3所示。对于所有设置,我们的攻击准确率与特征距离指标均优于PPA [5]。
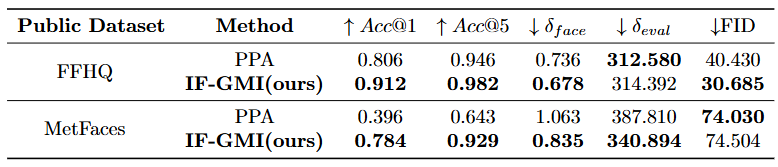
表2 以CelebA为私有数据集的攻击结果

表3 在不同架构的目标模型上的攻击结果
3.4 消融实验

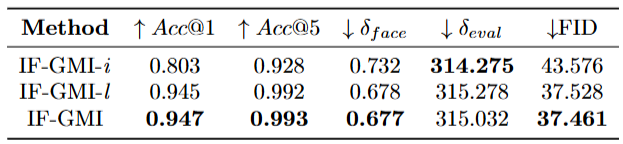
表4 消融实验结果
四、结论:

五、参考文献:
[1]Fang, H., Qiu, Y., Yu, H., Yu, W., Kong, J., Chong, B., Chen, B., Wang, X., Xia, S.T.: Privacy leakage on dnns: A survey of model inversion attacks and defenses. arXiv preprint arXiv:2402.04013 (2024)
[2]Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of stylegan. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8110–8119 (2020)
[3]Zhang, Y., Jia, R., Pei, H., Wang, W., Li, B., Song, D.: The secret revealer: Generative model-inversion attacks against deep neural networks. In: CVPR (2020)
[4]Chen, S., Kahla, M., Jia, R., Qi, G.J.: Knowledge-enriched distributional model inversion attacks. In: ICCV (2021)
[5]Struppek, L., Hintersdorf, D., Correira, A.D.A., Adler, A., Kersting, K.: Plug & play attacks: Towards robust and flexible model inversion attacks. In: ICML (2022)
[6]Nguyen, N.B., Chandrasegaran, K., Abdollahzadeh, M., Cheung, N.M.: Re-thinking model inversion attacks against deep neural networks. In: CVPR. pp. 16384–16393 (2023)
[7]Yuan, X., Chen, K., Zhang, J., Zhang, W., Yu, N., Zhang, Y.: Pseudo label-guided model inversion attack via conditional generative adversarial network. In: AAAI (2023)
