近日,哈尔滨工业大学(深圳)施少怀教授课题组论文《AGoQ:Activation and Gradient Quantization for Memory-Efficient Distributed Training of LLMs》(作者:Wenxiang Lin, Juntao Huang, Luhan Zhang, Laiyi Li, Xiang Bao, Mengyang Zhang, Bing Wang, Shaohuai Shi)被CCF-A类国际顶级学术会议ICML2026接收。该论文由哈尔滨工业大学(深圳)计算机应用中心与华为计算产品线合作完成,通讯作者为施少怀教授。论文聚焦大语言模型(LLM)训练中的GPU内存瓶颈问题,提出了AGoQ系统——一种通过近4位激活值量化和8位梯度量化实现内存与通信双重优化的分布式训练方案,在英伟达64块 GPU集群上实现了最高52%的内存节省和1.34倍训练加速,同时在华为昇腾910平台上得到验证。
论文简介:
大语言模型规模的持续增长对训练过程中的GPU内存容量提出了严峻挑战。在模型参数、梯度、优化器状态和激活值这四大内存消费者中,激活值通常占据最大的内存比例,且随序列长度和批量大小线性增加。现有的量化压缩方案中,4位激活值量化极易导致显著的精度下降,而8位梯度量化则因All‑Reduce求和过程中的数据溢出问题,常常引发收敛变慢。为此,AGoQ系统提出了三项核心创新:
创新一:层感知激活值量化算法(LAAQ) 。从数值误差分析出发,系统评估了Transformer不同模块(注意力机制、前馈网络、层归一化、SiLU等)中激活值量化对梯度计算的影响。理论推导与实验均表明,注意力模块的量化误差远大于其他模块。因此,AGoQ仅对注意力之外的激活值进行分块FP4量化,而对注意力输出保持全精度存储,实现了近4位的平均存储位宽,在不显著放大梯度误差的前提下大幅节省内存。
创新二:流水线并行下的动态位宽补偿(DBCA‑PP) 。针对Megatron‑LM交错1F1B流水线调度中不同GPU存储激活值批次数量不均衡的问题(如四阶段配置下设备1存储11个微批激活值,而设备4仅存5个),AGoQ动态为各阶段分配差异化量级位宽——激活值批次较少的设备采用较高位宽(如6位/8位),批次较多的设备采用4位压缩,在不增加峰值内存的前提下补偿量化精度损失,使各阶段内存利用率趋于均衡。
创新三:精度保持的8位梯度量化(QuanGrad) 。通过分块量化与本地梯度累积的协同设计,有效缓解8位梯度在All‑Reduce求和过程中的溢出风险。同时将8位梯度通信与Megatron‑LM的序列并行机制深度融合,在200Gbps和10Gbps两种带宽条件下,较全精度梯度通信分别实现3.4倍和3.7倍的通信延迟降低。
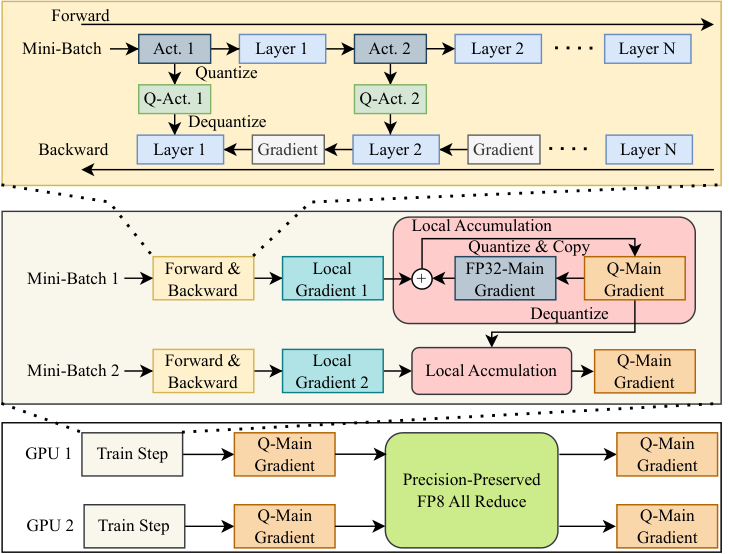
图1 整体流程图
实验结果:
在64 GPU集群(NVIDIA A6000,200Gb/s InfiniBand)上开展的大量实验,覆盖LLaMA2‑7B/13B、LLaMA3‑8B和CodeLLaMA‑34B等多种主流大模型,并与Megatron‑LM、DeepSpeed、ZeRO系列及COAT等代表性系统进行了全面对比。主要结果如下:
内存节省:相较于全精度基线Megatron‑LM,AGoQ将激活值内存减少约72%,梯度内存减少75%,整体内存占用降低高达52%。
训练加速:在LLaMA2‑13B模型、序列长度80K的配置下,AGoQ较Megatron‑LM和ZeRO‑1实现1.34倍端到端训练加速;在64 GPU/72种配置的规模化评估中,平均加速比达1.23×(相较于Megatron‑LM)和1.19×(相较于ZeRO‑1)。
收敛精度保持:在OpenWebText语料上预训练LLaMA2‑7B和LLaMA3‑8B各20亿token,AGoQ的损失曲线与全精度基线高度吻合;在VLM下游任务上,两者损失几乎重叠。相比之下,微软FP8‑AllReduce方法在相同配置下损失明显偏高。
与COAT对比:在OLMo‑1B模型24K序列长度下,AGoQ减少31%内存占用并匹配训练速度;32K序列下实现1.1倍加速。
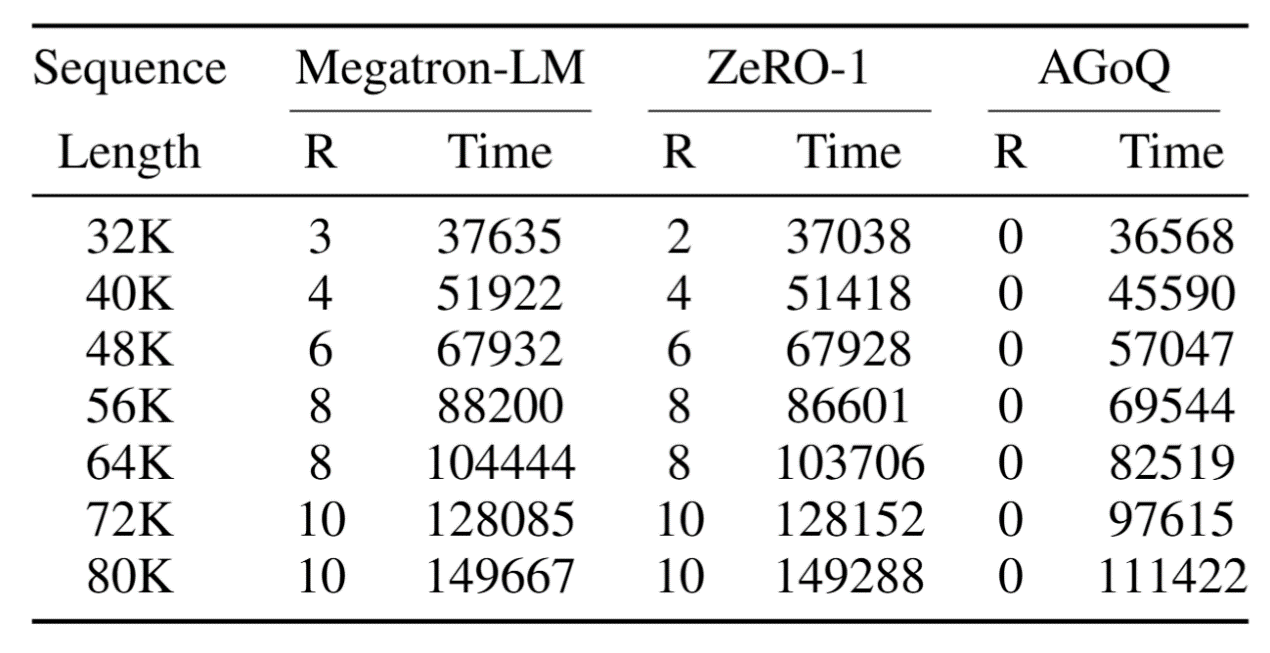
表1 实验结果对比
作者介绍:
第一作者:林稳翔,哈尔滨工业大学(深圳)2024级博士研究生,研究方向为高性能计算,分布式训练框架优化。目前以第一作者身份发表 CCF-A类会议SIGCOMM一篇,INFOCOM一篇,ICML一篇,共同一作发表ASPLOS一篇。
通讯作者:施少怀,哈尔滨工业大学(深圳)计算机科学与技术学院教授、博士生导师,2022年入选国家级青年人才计划,“鹏城孔雀计划”特聘岗位B档。2020年在香港浸会大学获得博士学位,2020-2022年在香港科技大学计算机科学与工程系任研究助理教授。研究兴趣为机器学习系统和高性能计算,在相关领域共发表文章60余篇,包括TPDS、ASPLOS、EuroSys、INFOCOM、ICLR、MLSys等顶刊或顶会论文,总谷歌学术引用4000余次,H-index为31。荣获国际会议IEEE DataCom 2018和IEEE INFOCOM 2021最佳论文奖以及IEEE ICDCS 2025杰出论文奖。入选2024年和2025年度“全球前2%顶尖科学家榜单”,荣获2024年度华为计算产品线最佳技术合作奖和2024年度华为“昇腾科研创新卓越贡献者”奖项。同时担任多个学术服务,包括国际智联网络系统学会理事、IEEE/ACM IWQoS 2024 Poster共同主席、ACM MobiSys 2021研讨会 EMDL程序委员会共同主席等。主持多项国家级、市级和华为合作项目。
初审 | 施少怀
复审 | 漆舒汉
终审 | 王 轩
